Image Segmentation: The First Step In 3-D Imaging
By Y. Ted Wu, Ph.D. Able Software LLC.
Copyright (C) 1999, All rights reserved.
Introduction
A basic task in 3-D image processing is the segmentation of an image which classifies voxels/pixels into objects or groups. 3-D image segmentation makes it possible to create 3-D rendering for multiple objects and perform quantitative analysis for the size, density and other parameters of detected objects.
A raw 3-D image, whether it is CT, MRI or microscopy image, comes as a 3D array of voxels or pixels. Each voxel has a greyscale range from 0 to 65535 in the 16-bit pixel case or 0 to 255 in the 8-bit pixel case. Most medical imaging systems generates images using 16-bit greyscale range. A 3D image typically has a large number of pixels and is very compute intensive for processing such as segmentation and pattern recognition. A segmented image on the other hand provides a much simpler description of objects that allows the creation of 3D surface models or display of volume data.
While the raw image can be readily displayed as 2-D slices, 3-D analysis and visualization requires explicitly defined object boundaries, especially when creating 3D surface models. For example, to create a 3-D rendering of a human brain from a MRI image, the brain needs to be identified first within the image and then its boundary marked and used for 3D rendering. The pixel detection process is called image segmentation, which identifies the attributes of pixels and defines the boundaries for pixels that belong to same group. Additionally, measurements and quantitative analysis for parameters such as area, perimeter, volume and length, can be obtained easily when object boundaries are defined.
Because of the importance of identifying objects from an image, there have been extensive research efforts on image segmentation for the past decades. A number of image segmentation methods have been developed using fully automatic or semi-automatic approaches for medical imaging and other applications.
Here, we will discuss some of the image segmentation methods implemented in 3D-DOCTOR, a 3-D imaging software developed by Able Software (www.ablesw.com) and how they can be used.
Vector-Based Object Boundaries
Traditionally, 3D imaging systems uses a raster-based data structure, which is similar to a volume image, where each pixel has a code to indicate what object it belongs to at that position. The advantage of this structure is simple and almost identical to the original image, but it requires a huge amount of computer memory to store and computing power to process. It is also difficult for interactive on-screen editing when a 3-D object contains a huge number of pixels. This is due to the fact that each pixel has to be updated or touched when their attributes are changed. Although raster-based surface rendering algorithms are quite robust, the resulting surface model can have millions of surface triangles or polygons which may not be suitable for applications such as rapid prototyping.
On the other hand, vector-based data structure provides a more efficient way to represent regions and objects. When using vector-based data structure, a line segment consists of only two points while a region or polygon is formed by a group of connected lines. Because of the abstract mathematical form, the vector-based structure uses very little computer memory and is easy to modify and fast to display. When modifying a boundary, moving one point on a line segment to a new location may be all it needs to change the shape. Figure 1 shows the difference between raster-based and vector-based data structures.
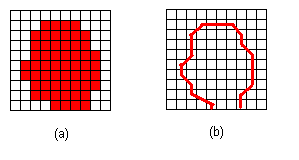
3D-DOCTOR uses vector-based data structure for object boundaries and regions of interest for easier interactive editing and better processing and display performance. The raster-based data structure is used for image data and volume data display and handling.
Image Segmentation By Thresholding
Defining a region of interest before image segmentation will limit the processing the defined region so no computing resource is wasted for other irrelevant areas. This also reduces the amount of editing needed after image segmentation because object boundaries are generated within the defined regions.
Image segmentation by thresholding is a simple but powerful approach for images containing solid objects which are distinguishable from the background or other objects in terms of pixel intensity values. The pixel thresholds are normally adjusted interactively and displayed in real-time on screen. When the values are defined properly, the boundaries are traced for all pixels within the range in the image. Greyscale thresholding works well when an image that has uniform regions and contrasting background. Following section discusses some of the image segmentation methods implemented in the software.
Fully automatic image segmentation by global thresholding
The histogram of the 3-D image is first calculated and an optimal threshold to divide the image into object and background is derived by finding the valley from the histogram. See Figure 2.
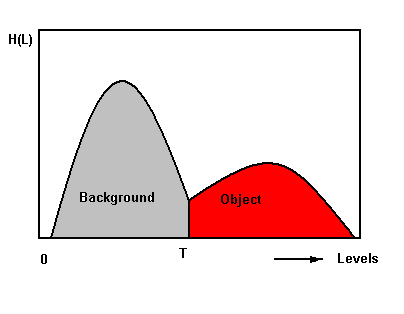
Interactive Thresholding
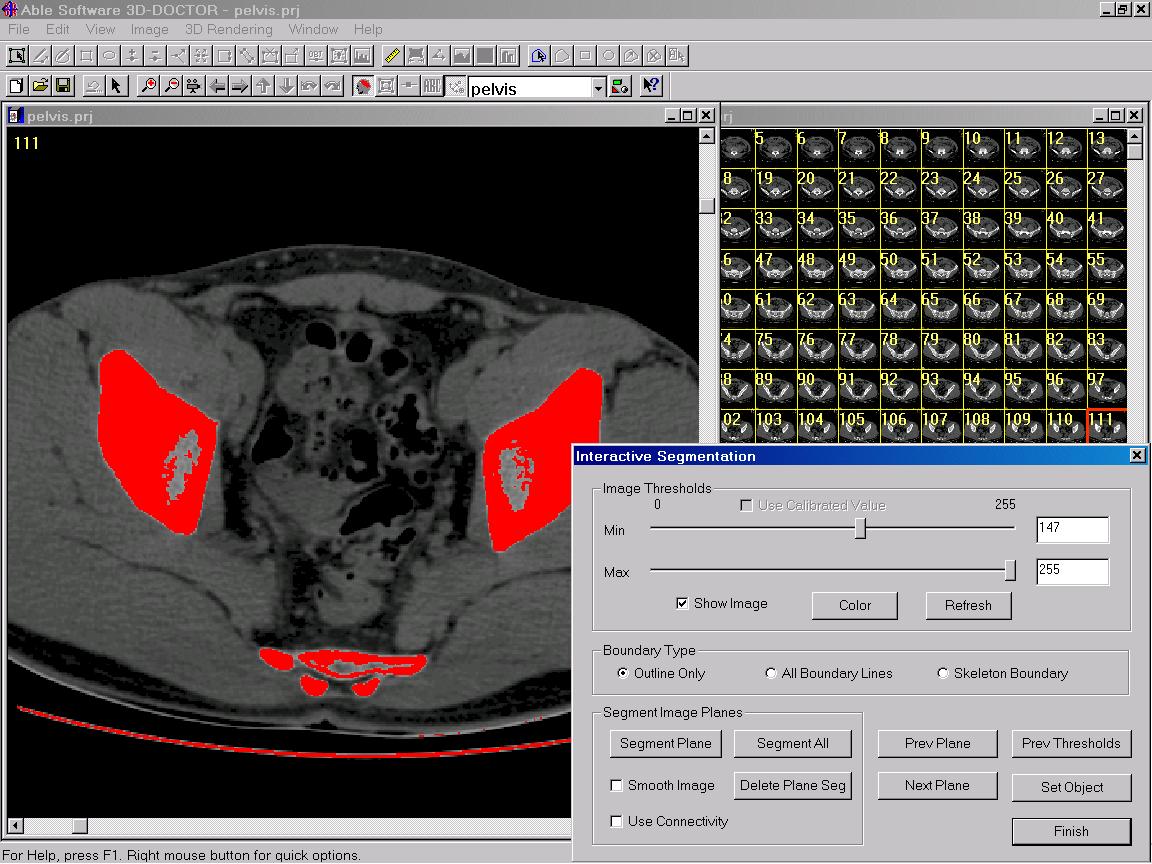
This technique uses two values to define the threshold range. The thresholds are adjusted interactively by showing all pixels within the range in one color and all pixels outside the range to a different color. Since the thresholds are displayed in real-time on the image, the threshold range can be defined locally and varied from slice to slice. All pixels within the range are segmented to generate the final boundaries. Figure 3 shows the result of interactive thresholding.
Texture-Based Segmentation
While image texture has been defined in many different ways, a major characteristic is the repetition of a pattern or patterns over a region. The pattern may be repeated exactly, or as a set of small variations on the theme, possibly a function of position. For medical images, because objects are normally certain type of tissues, such as blood vessels, brain tissue, bones and etc, they provide a rich set of texture information for image segmentation. For some objects with strong texture, texture based segmentation generates more accurate object boundary than thresholding based methods.
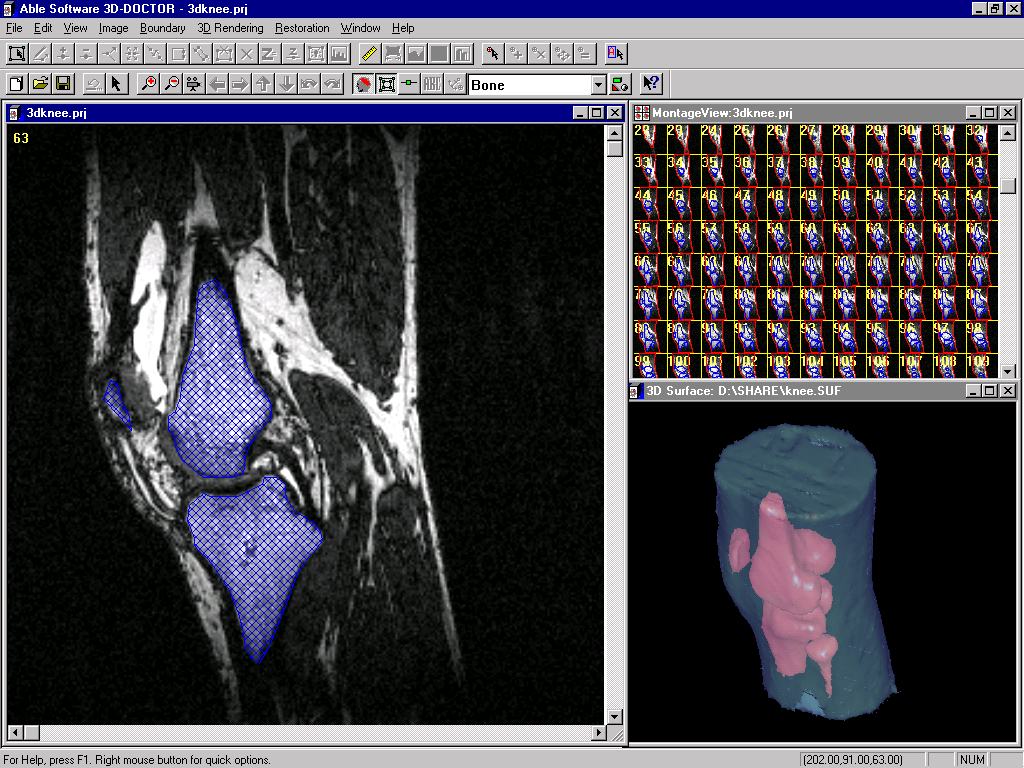
The texture based segmentation starts with a user defined training area, where texture characteristics are calculated and then applied as a pixel classifier to other pixels in one cross-section image or the entire volume to separate them into groups. Object boundaries are traced and their topological relationship are established. Figure 4 shows an example of texture based segmentation.
Vector-Based Boundary Editing
Regardless what segmentation method is used, automated methods often can not generate perfect object boundaries. For a 3-D imaging software, an easy-to-use boundary editor is a indispensable tool to allow modification or even manual tracing of objects which have faint texture or weak edges.
While raster-based pixel editing is doable, it involves modification of large number of pixels for even a small region. However, vector-based boundaries are easy to edit and have better integration with the original image. They are displayed right on top of the original image and treated as additional graphics layers. Vector-based boundary editing makes it possible to do 3D imaging and analysis on the low end PCs without any performance degrading.
Multiple-object integration is another advantage of vector-based editing. Multiple objects can be displayed in different colors and edited the same time in the same space where the original image is displayed. For raster-based method, this is sometimes difficult to do for multiple objects, especially when they overlap or one as part of another.